Primus FinAgent-4B : Exploring the Frontier of Verifiable Financial Reasoning in Small Language Models

Ranti Dev, Ayush Jasuja and Jatin Mehta
TL;DR 4B = 235B in Financial Analysis
We took the Qwen3-4B-Instruct-2507 model and trained it with reinforcement learning (GRPO) to answer questions about SEC 10-K filings by using tools — discovering tables, inspecting schemas, writing SQL, and doing arithmetic. The interesting finding isn’t a leaderboard number. It’s that the behavior which separates a useful financial agent from a useless one shows up early and is legible: the model stops guessing and starts discovering, reads its own error messages, and corrects itself.
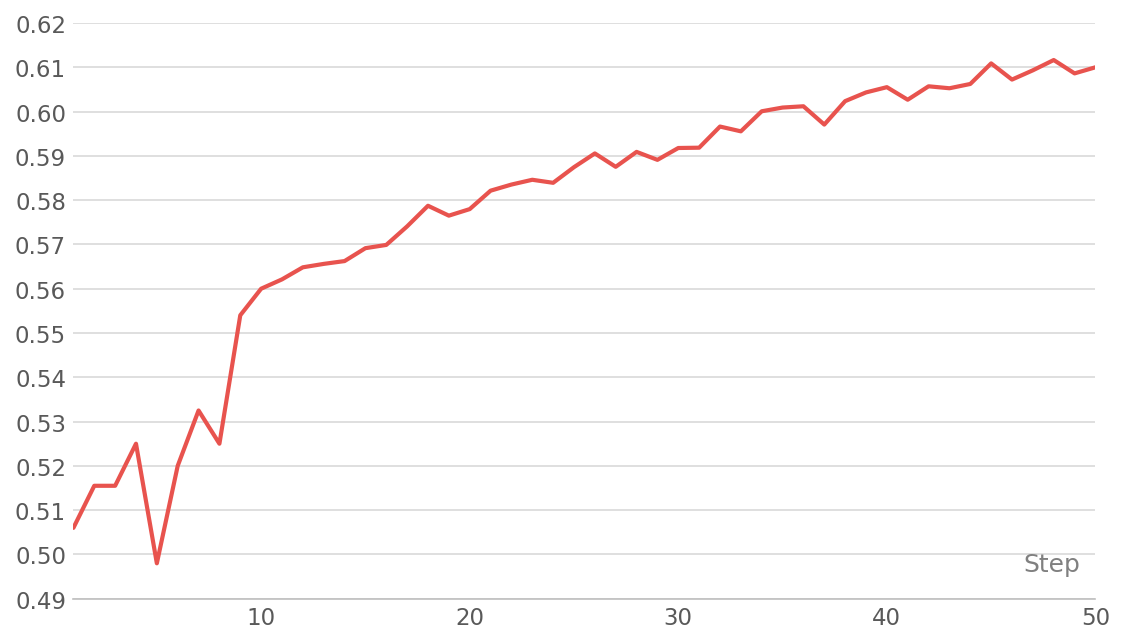
On a 100-question slice of the held-out test set, an early checkpoint already scores 53.0% pass@1 — climbing to 60.1% by 50 training steps — up from a 48.5% untrained baseline, and it inspects the correct source tables 73.6% of the time. But the number that convinced us is the single, unedited trajectory below.
The Thesis: Discipline Beats Scale
When a model fails at agentic financial analysis, the reflex is to scale up — 8B, 70B, 235B. But auditing a 10-K isn’t a test of raw intelligence. It’s a test of procedure: do you know the schema, do you respect tool constraints, do you read the error and adapt, or do you improvise?
A 235B generalist tends to guess a table name, get an error, guess again, and then hallucinate a plausible-sounding number. A small model trained for the task learns the opposite habit. It treats the data environment as something to be queried, not assumed. Here’s that habit, caught in the act.
Watch It Think
Question (company: `anthem`): What is the proportion of Level III fair value measurements to the total carrying value of Other invested assets as of December 31, 2024?
Gold answer: 0.950 — i.e. 610 / 642.
Step 0 — it makes a plan before touching anything.
“To answer the question … I need to: 1. Identify the relevant financial tables for Anthem using get_table_names. 2. Inspect the table descriptions and columns … 3. Extract the required values … 4. Compute the ratio.”
Step 1 — it discovers the table instead of guessing it.
“The table names include one that seems most relevant to fair value measurements and investments: elv_CarryingAndFairValuesByLevelOfFinancialInstrumentsNotRecordedAtFairValueOnConsolidatedBalanceSheetTableTextBlock. … I will inspect its structure to confirm the presence of relevant columns.”
No human would guess that table name. The model didn’t either — it called get_table_names and picked from reality.
Step 2 — it reads the schema.
“The table contains: category, carrying_value, level_i, level_ii, level_iii, total …”
Step 3 — its first SQL query returns empty, and it diagnoses its own bug.
“The query returned an empty result, which suggests that the condition category = ‘Other invested assets’ AND category = ‘December 31, 2024’ is not valid — a row cannot satisfy two distinct conditions simultaneously.”
This is the moment. A generalist model usually repeats the same broken strategy. This one read the empty result as information and reasoned about why the query was wrong.
Step 5 — it hits a tool constraint and self-corrects.
“You’re absolutely right — I cannot use SELECT * as per the tool constraints. I must explicitly list the columns. … I will now retrieve the full row … with explicit column selection.”
Step 6 — it lands the answer.
“carrying_value: $642 … level_iii: $610 …”
610 / 642 = 0.950. Correct, to the gold digit.
One trajectory, and you’ve seen the whole skill: plan → discover → inspect → fail → diagnose → adapt → compute. That’s not intelligence. It’s discipline — and it’s exactly what RL on a small model installs.
How It’s Trained (Briefly)
• Agent: a multi-turn ReAct loop with four tools — get_table_names, get_table_info, sql_query, calculator — over an in-memory SQLite of ~6,900 tables from 207 companies’ filings.
• Algorithm: GRPO (Group Relative Policy Optimization). Each training example is a full multi-turn trajectory; the policy is updated on the end-of-trajectory reward across the whole sequence of reasoning and tool calls.
• Reward: binary. 1 if an LLM judge (gpt-5-nano) rules the final answer matches ground truth, 0 otherwise — plus a small bonus for inspecting the right tables. The sparse signal forces the model to optimize the entire chain, not game intermediate steps.
• Compute: 8×A100-80GB, full-parameter training with FSDP2 + optimizer offload, vLLM for rollouts.
What the Numbers Say
|
Metric |
Untrained
baseline |
Early
checkpoint |
+50
steps |
|
Pass@1 (100 test Qs) |
48.5% |
53.0% |
60.1% |
|
Right-table access |
— |
73.6% |
— |
|
Mean reward (train rollouts) |
~0.50 |
~0.56 and climbing |
— |
By 50 training steps, pass@1 climbs to 60.1% — a gain of more than 11 points over the untrained baseline and 7 over the early checkpoint. The model already discovers the correct tables three-quarters of the time, and the training reward is on the same upward trajectory the full run rides to ~72%. The behavior is there; more steps mostly sharpen it.
Where It Still Trips
Honesty check — here’s a miss, and it’s an instructive one.
Question: YoY % change in Anthem’s total Q4 cash dividend, 2023 → 2024. Gold: +7.803% ((373−346)/346).
The model’s tool use was flawless: it found us_gaap_DividendsDeclaredTableTextBlock and pulled the exact figures — $373M and $346M. Then it slipped on the reasoning, mapping the two years the opposite way and dividing by the wrong base:
“(346 − 373) / 373 × 100 ≈ −7.24%”
Right data, wrong normalization. The failures that remain at this stage aren’t “couldn’t find the number” — they’re “got the number, then reasoned about it slightly wrong.” That’s a much better class of error to be left with, and it’s the kind more training (and the table-access bonus) continues to grind down.
Takeaway
The deployable advantage of a specialist isn’t that it knows more. It’s that it has been trained to behave — to query instead of assume, to read errors instead of plowing past them, to respect the constraints of its tools. You can watch that behavior emerge in a single trajectory, on a 4B model, on one node of GPUs. For enterprise data work — finance, legal, healthcare, anywhere structured data meets tool use — that’s the property that actually ships.
Model link: https://huggingface.co/SpeedyLabsAI/Primus-FinAgent
Related Evidence: Why Reasoning Compresses but Knowledge Doesn’t
Our FinQA result — a 4B model trained to a disciplined, tool-using procedure — sits inside a broader pattern that other recent work makes explicit. The clearest articulation comes from the VibeThinker-3B technical report (Sina Weibo, June 2026), which argues that not all model capabilities scale with parameters the same way. The figures and claims below are as reported by that paper’s authors, who are presenting their own model; we treat them as a useful framing rather than as independently verified results.
The Parametric Compression-Coverage Hypothesis
The paper’s central claim is that foundational capabilities differ not only in how much parameter capacity they require, but in the structural form of that demand. It splits capabilities into two kinds:
• Parameter-dense capabilities — math, coding, verifiable reasoning. The core challenge here isn’t memorizing open-domain facts; it’s search, constraint satisfaction, error correction, and multi-step composition inside a structured solution space. The authors argue this can be compressed into a compact, reusable “reasoning core” that does not need many parameters.
• Parameter-expansive capabilities — long-tail knowledge. Knowledge-intensive and general-purpose abilities require broad coverage over open-domain facts, domain-specific concepts, semantic associations, and long-tail scenarios. The paper frames this as fundamentally a coverage problem that genuinely scales with parameter count — not something a small reusable core can stand in for.
The Evidence They Offer
VibeThinker-3B is the authors’ demonstration of the “dense” side. On verifiable reasoning tasks, the reported 3B model reaches scores they place in the band of flagship systems hundreds of times larger:
|
Benchmark
(as reported) |
VibeThinker-3B |
For
comparison |
|
AIME26 |
94.3 |
DeepSeek V3.2 (671B): 94.2 · Kimi
K2.5 (1T): 93.3 |
|
LiveCodeBench v6 |
80.2 |
DeepSeek V3.2: 80.8 ·
GPT-OSS-120B: 81.9 |
|
IMO-AnswerBench |
76.4 |
DeepSeek V3.2: 78.3 · GLM-5
(744B): 82.5 |
|
GPQA-Diamond (knowledge) |
70.2 |
Gemini 3 Pro: 91.9 · Kimi K2.5:
87.6 |
The decisive point for the hypothesis is the last row. On the verifiable benchmarks the 3B model matches or approaches the giants; but on GPQA-Diamond, a knowledge-heavy benchmark, it sits well behind them — 70.2, rising only to 72.9 with their claim-level test-time scaling, against ~86–92 for the flagship models. The authors read this gap not as a failure but as confirmation: reasoning compressed into 3B, knowledge did not.
The Decoupling Paradigm
From this the paper proposes a Reasoning-Knowledge Decoupling Paradigm: large models remain the natural home for broad knowledge breadth, because absorbing diverse semantics and long-tail distributions inherently needs massive capacity — while small models, given structurally constrained spaces and reliable training signals, are already sufficient to hold high-density reasoning depth. The takeaway the authors draw is that compact models aren’t merely a deployment-efficiency compromise; they’re a complementary path to frontier performance on the dense class of tasks.
This is the same property our FinQA work shows in miniature. The 10-K auditing task is verifiable and structured — schema discovery, SQL, arithmetic against ground truth — exactly the kind of “parameter-dense” problem the hypothesis predicts a small model can master once it’s trained to behave. The discipline we watched emerge in a single trajectory is what compression of a reasoning core looks like at the scale of one task.
Appendix: A Trajectory Gallery
Five more from the eval, spanning different question types. Every quote is the model’s own output.
1. Self-correction (Financial Ratio) — anthem ✓
“Proportion of Level III fair value measurements to total carrying value of Other invested assets.” Gold 0.950. The model discovered the table, ran a query that returned empty, diagnosed why (“a row cannot satisfy two distinct conditions simultaneously”), then hit the SELECT * tool constraint and corrected to explicit columns — landing 610/642 = 0.950. The whole skill in one trace.
2. Clean specialist solve (Contribution Share) — avery_dennison ✓
“What percentage of total income before taxes in 2024 came from foreign operations?” Gold 0.778. Four disciplined moves: discovered us_gaap_ScheduleOfIncomeBeforeIncomeTaxDomesticAndForeignTableTextBlock → read the schema (region × {2024, 2023, 2022}) → pulled foreign = $742.1M, total = $953.5M → calculator(742.1/953.5) → 77.83%. No wasted turns.
3. Complex skill from simple data (Mix Shift) — avery_dennison ✓
“Percentage-point change in the share of U.S. long-lived assets, 2023 → 2024.” Gold -0.009. This needs a two-step composition the model was never explicitly trained on: compute each year’s share (US ÷ total) from a dollar table, then difference them.
“2023: 662.8 / 1,826.0 = 0.3632 … 2024: 642.7 / 1,814.2 = 0.3544 … change = 0.3544 − 0.3632 = −0.0088”
Exactly the gold −0.009. It learned schema-discovery + SQL on simple single-table questions, and composed those skills into a multi-metric ratio-of-ratios on its own.
4. Duration ladder — avery_dennison ✓
“What share of the present value of lease liabilities is attributable to operating leases?”
“225.7 / 239.0 ≈ 0.944 … 94.4% … is attributable to operating leases.”
5. The honest miss (Growth YoY) — anthem ✗
“YoY % change in total Q4 cash dividend, 2023 → 2024.” Gold +7.803%. Tool use was flawless — it found us_gaap_DividendsDeclaredTableTextBlock and pulled the exact figures $373M and $346M. The slip was downstream: it mapped the years the opposite way and divided by the wrong base → (346−373)/373 = −7.24%. The remaining errors aren’t “couldn’t find the data,” they’re “found it, then normalized it slightly wrong” — a far better failure mode, and the one more training keeps shrinking.
The Discipline Gap
|
|
What
a guessing generalist does |
What
this model does |
|
Find data |
Guesses revenue_breakdown,
errors, guesses again |
Calls get_table_names,
picks the real us_gaap_… table |
|
On an error |
Repeats the failed query or
hallucinates |
Reads the empty result, diagnoses
the bug, adapts |
|
Tool limits |
Ignores constraints (SELECT *) |
“I cannot use SELECT * … I must
list columns explicitly” |
|
Final answer |
A plausible-sounding number |
610/642 = 0.950,
to the gold digit |